tar.gz 을 만들어보자
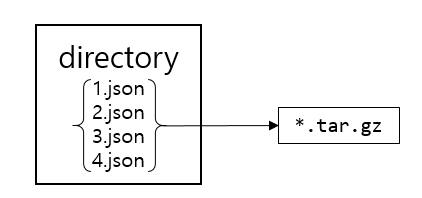
import tarfile
import os
target_dir = "/home/user/test"
tar = tarfile.open("./sample.tar.gz", "w:gz")
os.chdir(target_dir)
for f in os.listdir(target_dir):
file_name, extension = os.path.splitext(f)
print(extension)
if extension == ".json":
tar.add(f)
tar.close()os.listdir : directory 파일 search
os.path.splitext : 파일이름과 파일 확장자를 분리
'언어 > python' 카테고리의 다른 글
| # 기초 dictionary (0) | 2020.08.21 |
|---|---|
| pandas + matplotlib 을 이용하여 tistory 방문 관련 pie 차트 그리기 (0) | 2020.08.04 |
| 코로나 데이터 수집 (파이썬) (0) | 2020.07.18 |
| 네이버 python 지식인 답변 (0) | 2020.06.06 |
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
# 기초 dictionary
`정의:
키 : 값의 쌍의 집합

중요:
키는 고유해야 한다. (중복이 될 수 없다.)
주요 작업:
key와 함께 value 를 저장 -> 데이터 추가

del을 사용하여 "키 : 값" 쌍을 삭제할수 있다.

딕셔너리 정렬
A1) key값을 기준으로 정렬

sorted_dict_data 의 결과는 tuple 형태의 element로 구성된 list가 return 된다.
[('A', 165), ('C', 2), ('K', 1), ('Z', 0)]
이를 다시 dictionary로 변환하기 위한 작업이 아래 코드 이다. sorted_result

A2) value값을 기준으로 정렬


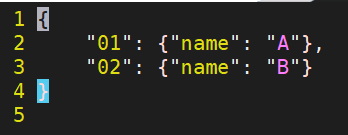
JSON FILE READ
-> 아래코드는 JSON 파일을 READ 하는 코드인데 json.load에 의해 반환되는 변수의 데이터 타입또한 dictionary

'언어 > python' 카테고리의 다른 글
| tar.gz 을 만들어보자 (0) | 2020.11.22 |
|---|---|
| pandas + matplotlib 을 이용하여 tistory 방문 관련 pie 차트 그리기 (0) | 2020.08.04 |
| 코로나 데이터 수집 (파이썬) (0) | 2020.07.18 |
| 네이버 python 지식인 답변 (0) | 2020.06.06 |
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
pandas + matplotlib 을 이용하여 tistory 방문 관련 pie 차트 그리기
수정 중 ( 내용 추가될 예정 - 8월4일 늦은 오후에... )
pandas 에서 수식(예를 들어 sum 과 같은)으로 작성된 셀 값은 nan 으로 처리 된다. (???)
import pandas as pd
from matplotlib import pyplot as plt
excel_file = "./test.xlsx"
data_frame = pd.read_excel(excel_file, sheet_name=0)
result = data_frame[["성별", "방문자수"]]
person = {"남자": 0, "여자": 0}
for x in result.values:
person[x[0]] = person[x[0]] + x[1]
eng_person = {"man": person["남자"], "woman": person["여자"]}
category = [x for x in eng_person.keys()]
data = [eng_person[y] for y in category]
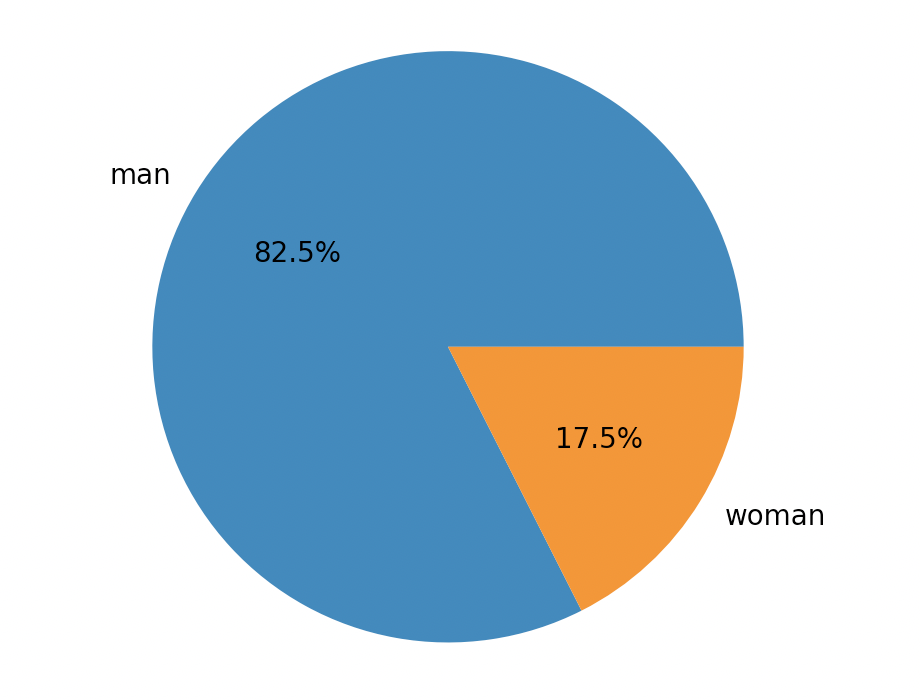
plt.pie(data, labels=category, autopct="%0.1f%%")
plt.show()
[ 엑셀 구조 ]

[ pie chart ]
'언어 > python' 카테고리의 다른 글
| tar.gz 을 만들어보자 (0) | 2020.11.22 |
|---|---|
| # 기초 dictionary (0) | 2020.08.21 |
| 코로나 데이터 수집 (파이썬) (0) | 2020.07.18 |
| 네이버 python 지식인 답변 (0) | 2020.06.06 |
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
코로나 데이터 수집 (파이썬)
#주말 토이프로젝트
1] 수집 사이트
https://news.google.com/covid19/map?hl=ko&mid=%2Fm%2F02j71&gl=KR&ceid=KR%3Ako
코로나바이러스(코로나19) - Google 뉴스
Google 뉴스에서 코로나19의 영향을 받는 지역에 관한 지도, 통계, 뉴스를 확인하세요.
news.google.com
2] 그래프
: 사용그래프 (altair)
참고 : https://partrita.github.io/posts/altair/


그래프 view source

vega-editor

값 수정 테스트
3] 코드 깃
https://github.com/sleep4725/Cor19
sleep4725/Cor19
Contribute to sleep4725/Cor19 development by creating an account on GitHub.
github.com
'언어 > python' 카테고리의 다른 글
| # 기초 dictionary (0) | 2020.08.21 |
|---|---|
| pandas + matplotlib 을 이용하여 tistory 방문 관련 pie 차트 그리기 (0) | 2020.08.04 |
| 네이버 python 지식인 답변 (0) | 2020.06.06 |
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
| pdf 변환 (0) | 2019.12.18 |
네이버 python 지식인 답변
'언어 > python' 카테고리의 다른 글
| pandas + matplotlib 을 이용하여 tistory 방문 관련 pie 차트 그리기 (0) | 2020.08.04 |
|---|---|
| 코로나 데이터 수집 (파이썬) (0) | 2020.07.18 |
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
| pdf 변환 (0) | 2019.12.18 |
| python으로 pdf 파일 read (0) | 2019.12.08 |
21대 국회의원 선거 크롤링
https://search.naver.com/search.naver?where=nexearch&sm=tab_etc&query=%ED%88%AC%ED%91%9C%EC%9C%A8
import requests
import urllib
import json
from bs4 import BeautifulSoup
import time
from elasticsearch import Elasticsearch
class Poll():
def __init__(self):
self._url = "https://search.naver.com/search.naver"
self._params = {"sm": "top_hty", "fbm": 0, "ie": "utf8"}
self._cllect_time = time.strftime("%Y%m%d%H%M%S", time.localtime())
self._total_data = list()
self._es = Elasticsearch (hosts=["http://", "http://", "http://"])
def url_req(self):
param_encode = urllib.parse.urlencode (self._params) +"&query={}".format("이시각 투표율")
url = self._url + "?" + param_encode
print (url)
session = requests.Session()
try:
html = session.get(url)
except:
print("요청 에러{}".format(self.total_data))
pass
else:
if html.status_code == 200 and html.ok:
bs_obj = BeautifulSoup(html.text, "html.parser")
print(bs_obj.title.string)
graph_view = bs_obj.select_one("ul.graph_view")
v2_list = graph_view.select("li.v2 > a")
for v in v2_list:
locals_name = v.select_one("strong.num_standard").string
percentages = v.select_one("span.graph_bar > span.num > span.num_data2").text
d = {"name": locals_name, "value": percentages[:-1], "cllct": self._cllect_time}
self._total_data.append(d)
if len(self._total_data) != 0:
#
# 데이터 파일 생성
#
self.mk_ndjson()
def mk_ndjson(self):
with open("/home/elastic/Desktop/nd_json_data/polling_{}.json".format(self._cllect_time), "a", encoding="utf-8") as f:
for i in range(0, len(self._total_data)):
f.write(json.dumps(self._total_data[i], ensure_ascii=False))
if i != len(self._total_data)-1:
f.write("\n")
f.close()
def __del__(self):
print("=============================================")
print("끝 : {}".format(time.strftime("%Y%m%d %H:%M:%S")))
if __name__ == "__main__":
print("=============================================")
print("시작 : {}".format(time.strftime("%Y%m%d %H:%M:%S")))
p = Poll()
p.url_req()
'언어 > python' 카테고리의 다른 글
| 코로나 데이터 수집 (파이썬) (0) | 2020.07.18 |
|---|---|
| 네이버 python 지식인 답변 (0) | 2020.06.06 |
| pdf 변환 (0) | 2019.12.18 |
| python으로 pdf 파일 read (0) | 2019.12.08 |
| 백준 2108 (0) | 2019.12.08 |
from pdflib import Document
import os
import base64
from ela_dir.Ela import Ela
class PDFObj():
def __init__(self):
#Ela.__init__(self)
self._targetPath="./pdf_dir"
def dirSearch(self):
os.chdir(self._targetPath)
cur = os.listdir()
for f in cur:
fname, fext = os.path.splitext(f)
if fext == ".pdf":
doc = Document(f)
print(doc.metadata)
for c, p in enumerate(doc):
strData = " ".join(p.lines).strip()
#encodedBytes = base64.b64encode(strData.encode("utf-8"))
#encodedStr = str(encodedBytes, "utf-8")
#e = {"page_" : c+1,
# "data_" : encodedStr}
e = {"page_" : c+1, "data_": strData}
print(e)
if __name__ == "__main__":
o = PDFObj()
o.dirSearch()'언어 > python' 카테고리의 다른 글
| 네이버 python 지식인 답변 (0) | 2020.06.06 |
|---|---|
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
| python으로 pdf 파일 read (0) | 2019.12.08 |
| 백준 2108 (0) | 2019.12.08 |
| from csv to json convert + logstash (0) | 2019.11.26 |
python으로 pdf 파일 read
from pdflib import Document
import os
import base64
class PDFObj():
def __init__(self):
self._targetPath="./pdf_dir"
def dirSearch(self):
os.chdir(self._targetPath)
cur = os.listdir()
for f in cur:
fname, fext = os.path.splitext(f)
if fext == ".pdf":
doc = Document(f)
print(doc.metadata)
for c, p in enumerate(doc):
print("{} ========================".format(p))
strData = " ".join(p.lines).strip()
encodedBytes = base64.b64encode(strData.encode("utf-8"))
encodedStr = str(encodedBytes, "utf-8")
print(encodedStr)
print(strData)
if c == 3:
exit(1)
if __name__ == "__main__":
o = PDFObj()
o.dirSearch()
테스트 환경
=> ubuntu 18.4
=> interpreter 3.6
'언어 > python' 카테고리의 다른 글
| 21대 국회의원 선거 크롤링 (0) | 2020.04.15 |
|---|---|
| pdf 변환 (0) | 2019.12.18 |
| 백준 2108 (0) | 2019.12.08 |
| from csv to json convert + logstash (0) | 2019.11.26 |
| 네이버 기사 크롤링 => elasticsearch 적재 (0) | 2019.07.12 |
from operator import itemgetter
from collections import Counter
import sys
class Q_2108():
def __init__(self):
self._numCnt = 0
self._numList = list()
self._totalSum = 0
def numSetting(self):
self._numCnt = int(sys.stdin.readline())
for _ in range(self._numCnt):
e = int(sys.stdin.readline())
self._totalSum += e
self._numList.append(e)
# 데이터 정렬
self._numList.sort()
def arithMean(self):
avr = round((float(self._totalSum)/len(self._numList)))
print(avr)
def middleNumber(self):
print(self._numList[int(len(self._numList)/2)])
def largeCnt(self):
modeDict = Counter(self._numList)
modes = modeDict.most_common()
if len(self._numList) > 1:
if modes[0][1] == modes[1][1]:
mod = modes[1][0]
else:
mod = modes[0][0]
else:
mod = modes[0][0]
print(mod)
# keyNum = set(self._numList)
# numCnt = [(k,self._numList.count(k)) for k in keyNum]
#
# # value값을 기준으로 정렬
# numCnt.sort(key= lambda e:(e[1], e[0]), reverse=True)
#
# # list는 순서를 보존한다.
# rawV = [i[1] for i in numCnt]
# largeNum = rawV[0]
# largeCnt = rawV.count(largeNum)
# largeArr = [i[0] for i in numCnt[:largeCnt]]
#
# if len(largeArr) == 1:
# print(largeArr[0])
#
# elif len(largeArr) > 1:
# if len(largeArr) == 2:
# print(largeArr[1])
# else:
# print(largeArr[len(largeArr)-2])
def numRange(self):
print(self._numList[len(self._numList)-1] - self._numList[0])
if __name__ == "__main__":
q = Q_2108()
q.numSetting()
q.arithMean()
q.middleNumber()
q.largeCnt()
q.numRange()'언어 > python' 카테고리의 다른 글
| pdf 변환 (0) | 2019.12.18 |
|---|---|
| python으로 pdf 파일 read (0) | 2019.12.08 |
| from csv to json convert + logstash (0) | 2019.11.26 |
| 네이버 기사 크롤링 => elasticsearch 적재 (0) | 2019.07.12 |
| naver music 크롤링 + elasticsearch (0) | 2019.05.22 |
from csv to json convert + logstash
import csv
import json
import os
import shutil
import subprocess
import time
#
class ConvJson():
def __init__(self):
# 대상 디렉토리
self._targetPath = r""
# json 이동 디렉토리
self._jsonPath = "jsonDir"
# field_name
self._fieldName = ("a", "b", "c")
# logstash path
self._logstashRun = ""
self._targetConfDir = ""
def csvRead(self):
# 디렉토리 이동
os.chdir(self._targetPath)
# file list
fileList = os.listdir()
for f in fileList:
fileAbsPath = os.path.abspath(f)
fileName, fileExtension = os.path.splitext(fileAbsPath)
if fileExtension == ".csv":
try:
csvFile = open(fileAbsPath, "r", encoding="utf-8")
next(csvFile)
except FileNotFoundError as E:
print(E)
exit(1)
else:
""" ndjson 파일로 변환
"""
try:
jsonFile = open("{}.json".format(fileName), "w", encoding="utf-8")
except:
print("file error")
exit(1)
else:
reader = csv.DictReader(f=csvFile, fieldnames=self._fieldName, delimiter="|")
data = list(reader)
for x in range(0, len(data)):
# json.dump(data, fp=jsonFile)
if x != len(data)-1:
strData = json.dumps(data[x]) + "\n"
else:
strData = json.dumps(data[x])
jsonFile.write(strData)
jsonFile.close()
csvFile.close()
def jsonFileMov(self):
# 디렉토리 이동
os.chdir(self._targetPath)
# file list
fileList = os.listdir()
for f in fileList:
fileAbsPath = os.path.abspath(f)
fileName, fileExtension = os.path.splitext(fileAbsPath)
if fileExtension == ".json":
try:
shutil.move("{}.json".format(fileName), self._targetPath + "\\" + self._jsonPath)
except OSError as E:
print("파일 이동 에러")
print(E)
exit(1)
else:
print ("이동 성공")
def logstashInsert(self):
# 디렉토리 이동
os.chdir(self._targetPath + "\\" + self._jsonPath)
# file list
fileList = os.listdir()
for f in fileList:
fileAbsPath = os.path.abspath(f)
command = self._logstashRun + " -f " + self._targetConfDir + " < " + fileAbsPath
p = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, shell=True)
stdout, _ = p.communicate()
print(stdout)
print("indexing complate")
print("=======================================================")
time.sleep(5)
def main():
o = ConvJson()
o.csvRead()
o.jsonFileMov()
if __name__ == "__main__":
main()
'언어 > python' 카테고리의 다른 글
| python으로 pdf 파일 read (0) | 2019.12.08 |
|---|---|
| 백준 2108 (0) | 2019.12.08 |
| 네이버 기사 크롤링 => elasticsearch 적재 (0) | 2019.07.12 |
| naver music 크롤링 + elasticsearch (0) | 2019.05.22 |
| 네이버 뉴스 크롤링 + 형태소 (0) | 2019.05.01 |
